LangChain:入门-本地化部署-接入大模型(8)
LangChain核心模块
- 模型(models) : LangChain 支持的各种模型类型和模型集成。
- 提示(prompts) : 包括提示管理、提示优化和提示序列化。
- 链(chains) : 链不仅仅是单个 LLM 调用,还包括一系列调用(无论是调用 LLM 还是不同的实用工具)。LangChain 提供了一种标准的链接口、许多与其他工具的集成。LangChain 提供了用于常见应用程序的端到端的链调用。
- 索引(indexes) : 与您自己的文本数据结合使用时,语言模型往往更加强大——此模块涵盖了执行此操作的最佳实践。
- 代理(agents) : 代理涉及 LLM 做出行动决策、执行该行动、查看一个观察结果,并重复该过程直到完成。LangChain 提供了一个标准的代理接口,一系列可供选择的代理,以及端到端代理的示例。
- 内存(memory)也叫记忆存储 : 内存是在链/代理调用之间保持状态的概念。LangChain提供了一个标准的内存接口、一组内存实现及使用内存的链/代理示例。
为了让能够更好的理解这六个核心模块,举个例子:
我们在使用使用大模型,首先就要使用模型对接。对接好了,我们怎么开始想怎么问大模型的问题(提示词),接着想好怎么问他,我们需要穿起来(链)。现在要强大我们的大模型,需要让他拥有额外知识(索引)和代替我们做一些工作(代理).再问问的时候我希望他拥有记忆(内存)
如何接入大模型
原生openai调用大模型
当你有了openai的key,你就可以使用opanai的模块进行调用
pip install openai==0.28
import os
import openai
def get_completion(prompt,model="gpt-3.5-turbo"):
messages=[{"role":"user","content":prompt}]
response=openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message["content"]
if __name__ == "__main__":
# import your OpenAI key (put in your .env file)
# 从.env文件中导入OpenAI的API密钥
with open(".env", "r") as f:
env_file = f.readlines()
envs_dict = {
key.strip("'"): value.strip("\n")
for key, value in [(i.split("=")) for i in env_file]
}
os.environ["OPENAI_API_KEY"] = envs_dict["OPENAI_API_KEY"]
# 第一步这是openai的key
openai.api_key = os.environ["OPENAI_API_KEY"]
print(get_completion("你好"))
返回结果
您好!有什么可以帮助您的吗
使用LangChain封装的OpenAI模块
环境准备
首先你需要下载你的大模型,这里用通义千问7B举例:
https://www.modelscope.cn/models/qwen/Qwen-7B-Chat/files

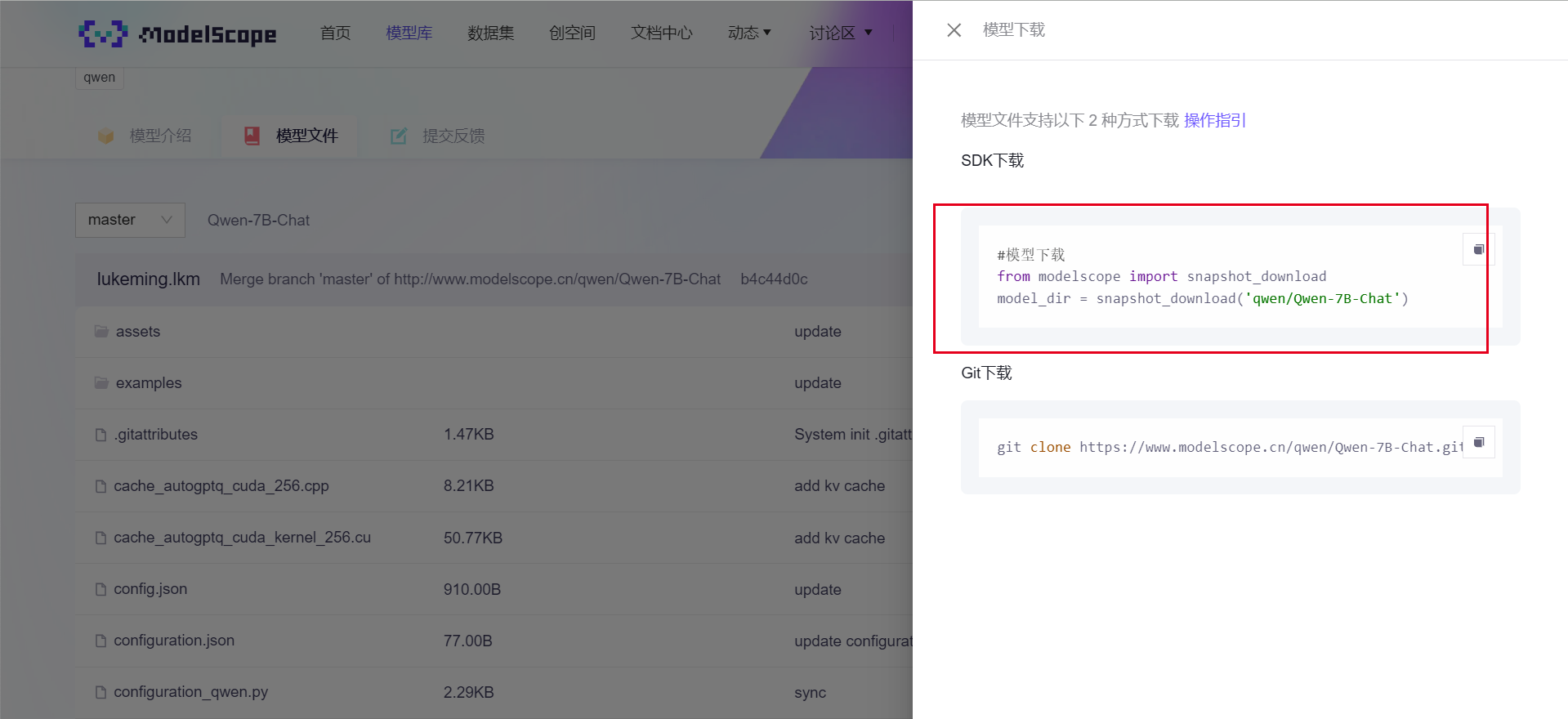
在下载之前你需要安装环境
pip install openai==0.28
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
pip install transformers_stream_generator
pip3 install -U modelscope
# 对于国内的用户,您可以使用以下命令进行安装:
# pip3 install -U modelscope -i https://mirror.sjtu.edu.cn/pypi/web/simple
默认是在/root/.cache文件夹,这里可以local_dir_root 指定下载位置
from modelscope.hub.snapshot_download import snapshot_download
local_dir_root = "/root/autodl-tmp/models_from_modelscope"
snapshot_download('qwen/Qwen-7B-Chat', cache_dir=local_dir_root)
启动模型
拉去官方的demo,一般模型都有自己的demo,大家可以去看看
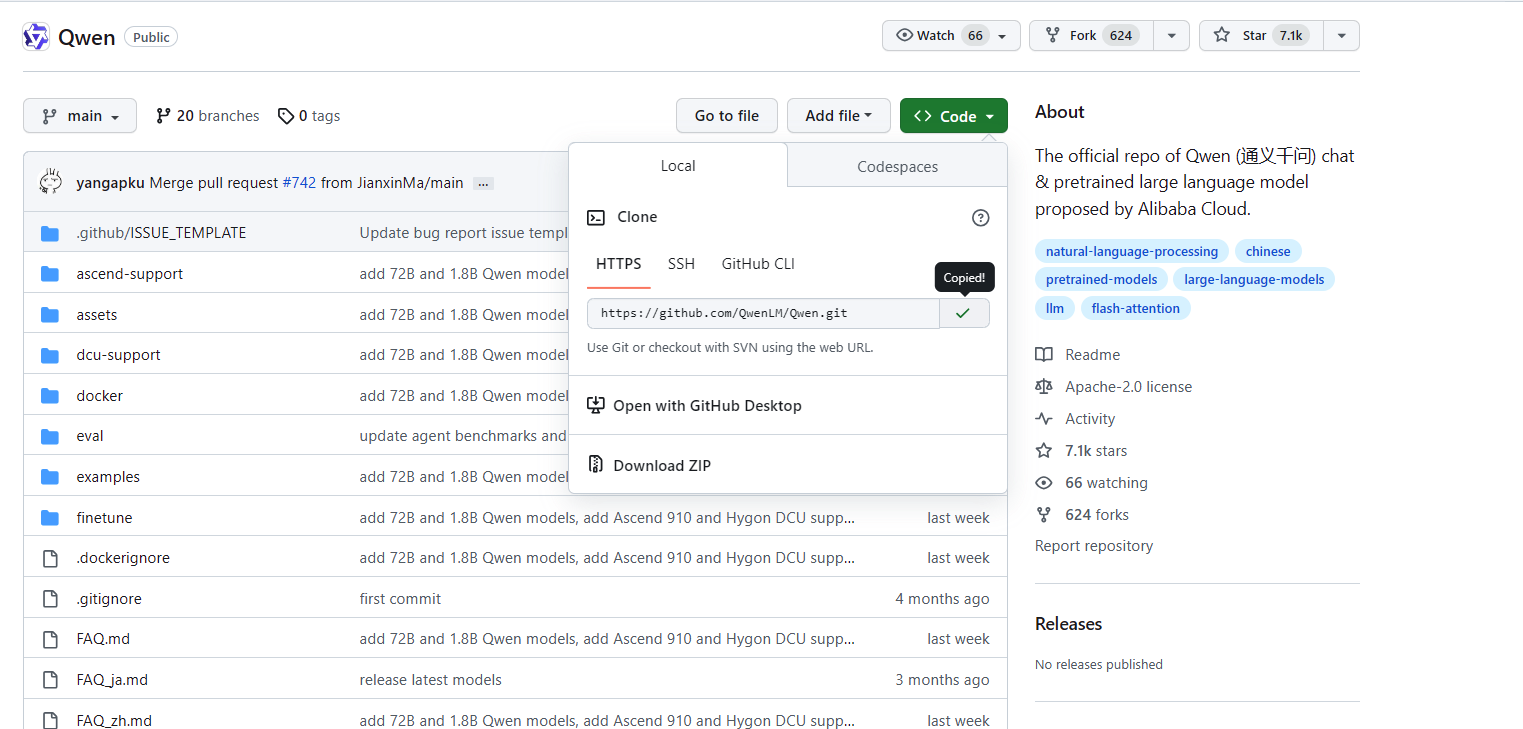
git clone https://github.com/QwenLM/Qwen.git
修改Qwen里面的openai_api地址为真实的地址
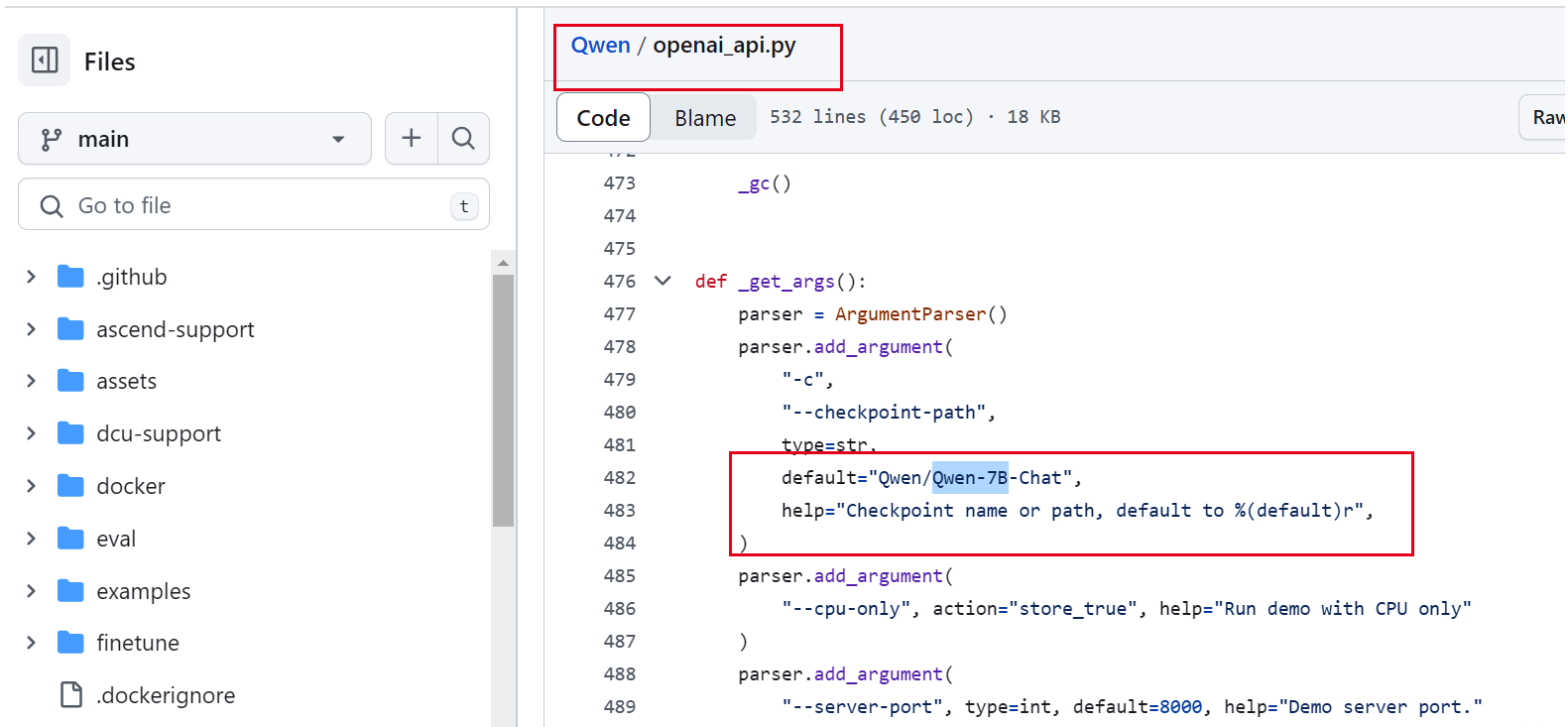
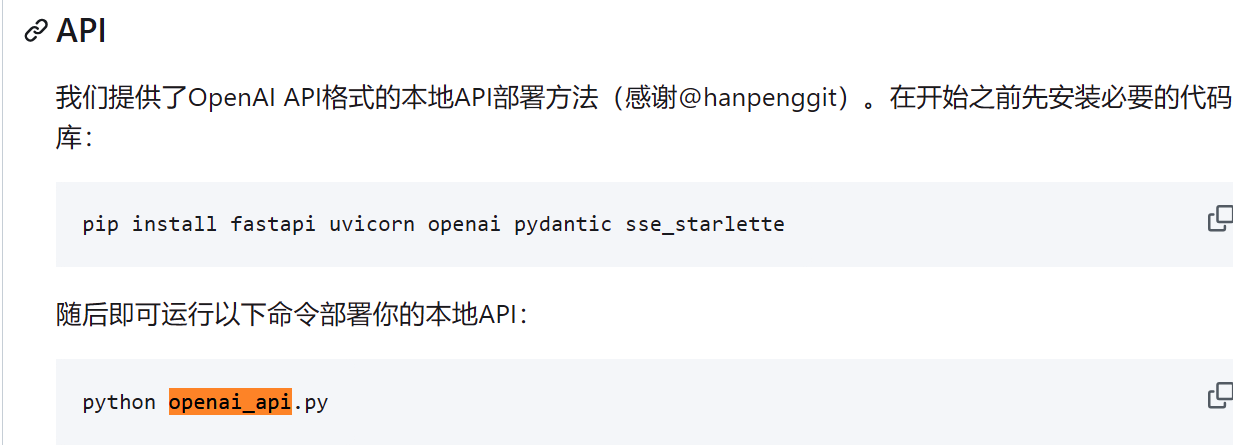
然后就可以正常启动了
pip install openai==0.28
pip install -r requirements.txt
pip install fastapi uvicorn openai pydantic sse_starlette
python openai_api.py
可以携带自己定义的参数
--checkpoint-path 增量模型地址
--cpu-only cpu启动
--server-port 服务端口默认8000
--server-name 服务ip默认127.0.0.1
---disable-gc在生成每个响应后禁用GC。
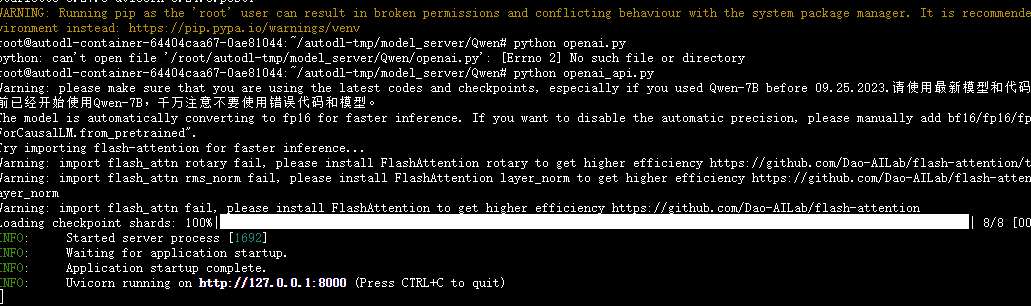
使用模型
当然此时我们还是可以使用openai的模块进行调用
import openai
openai.api_base = "http://localhost:8000/v1"
openai.api_key = "none"
# 使用流式回复的请求
for chunk in openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=True
# 流式输出的自定义stopwords功能尚未支持,正在开发中
):
if hasattr(chunk.choices[0].delta, "content"):
print(chunk.choices[0].delta.content, end="", flush=True)
# 不使用流式回复的请求
response = openai.ChatCompletion.create(
model="Qwen",
messages=[
{"role": "user", "content": "你好"}
],
stream=False,
stop=[] # 在此处添加自定义的stop words 例如ReAct prompting时需要增加: stop=["Observation:"]。
)
print(response.choices[0].message.content)
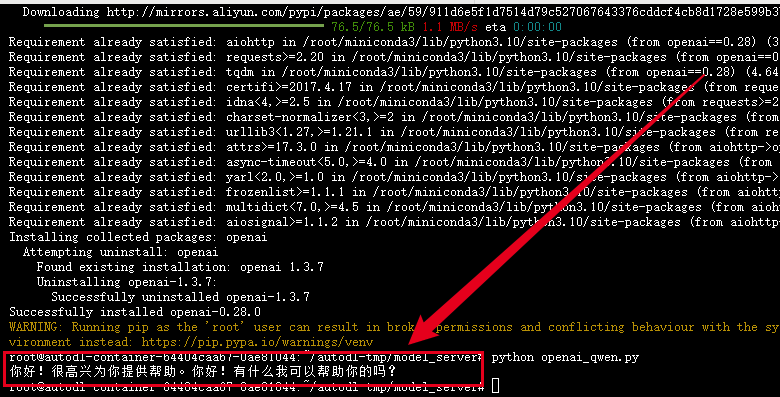
当然应为我们选择LangChain最为我们的中间件,我们也可以使用LangChain封装的模块使用
pip install langchain
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
llm = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
instructions = """
你将得到一个带有水果名称的句子,提取这些水果名称并为其分配一个表情符号
在 python 字典中返回水果名称和表情符号
"""
fruit_names = """
苹果,梨,这是奇异果
"""
# 制作结合说明和水果名称的提示
prompt = (instructions + fruit_names)
# Call the LLM
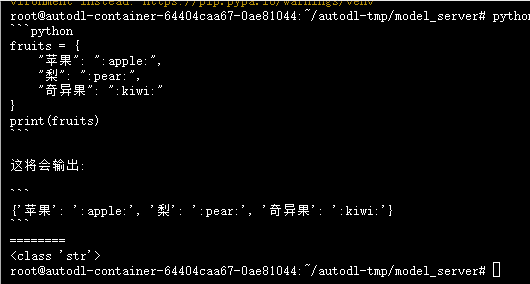
output = llm([HumanMessage(content=prompt)])
print (output.content)
print("========")
print (type(output.content))
# 苹果: 🍎梨: 🥐奇异果: 🍓
# ========
#
Was this helpful?
0 / 1